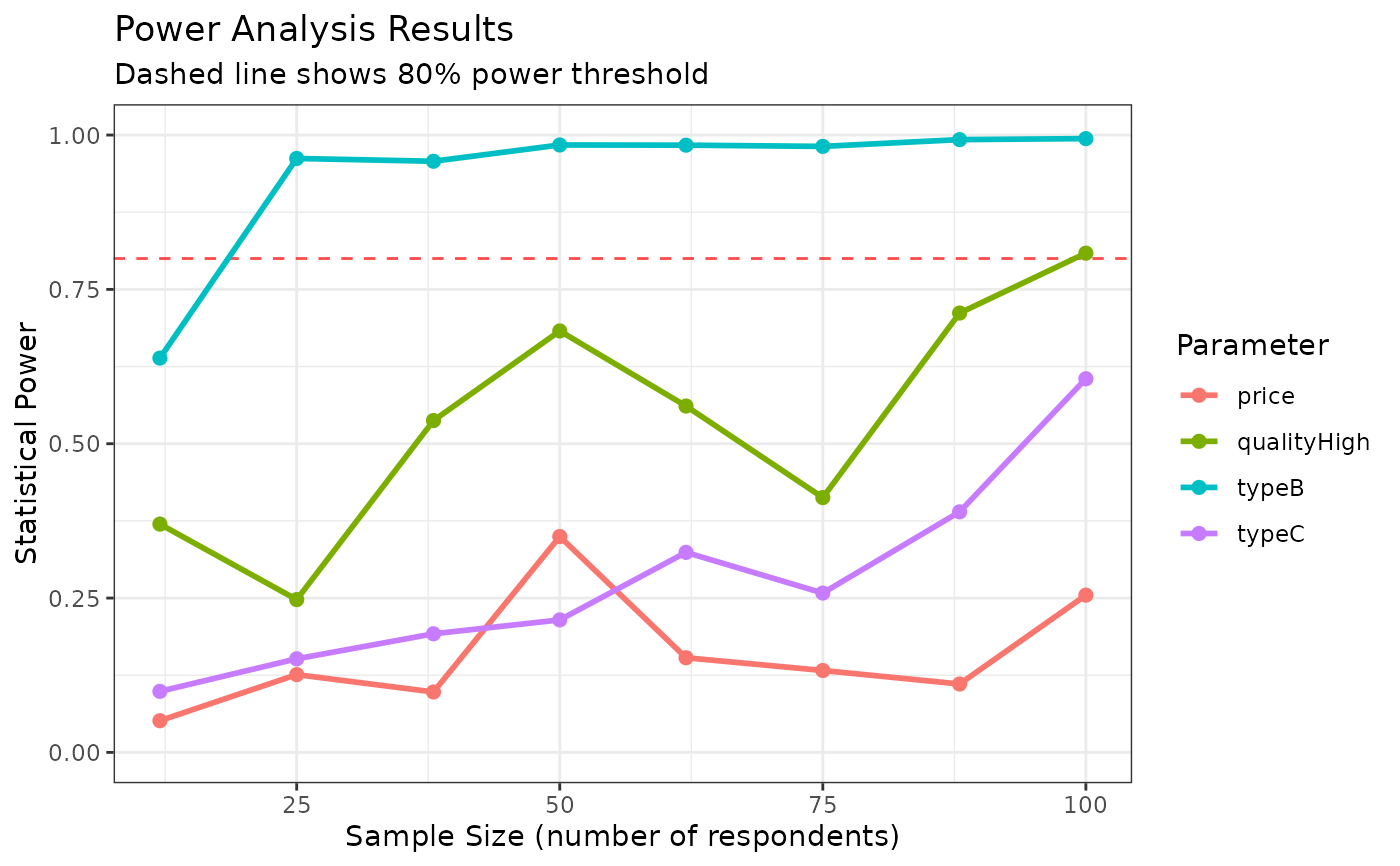
This function estimates the same model multiple times using different sample sizes to assess statistical power. It returns both the estimated models and a summary of coefficient estimates, standard errors, and power statistics.
Usage
cbc_power(
data,
outcome = "choice",
obsID = "obsID",
pars = NULL,
randPars = NULL,
n_breaks = 10,
n_q = NULL,
panelID = NULL,
alpha = 0.05,
return_models = FALSE,
n_cores = NULL,
...
)Arguments
- data
A data frame containing choice data. Can be a
cbc_choicesobject or any data frame with the required columns.- outcome
Name of the outcome variable column (1 for chosen, 0 for not). Defaults to "choice".
- obsID
Name of the observation ID column. Defaults to "obsID".
- pars
Names of the parameters to estimate. If NULL (default), will auto-detect from column names for
cbc_choicesobjects.- randPars
Named vector of random parameters and their distributions ('n' for normal, 'ln' for log-normal). Defaults to NULL.
- n_breaks
Number of sample size groups to test. Defaults to 10.
- n_q
Number of questions per respondent. Auto-detected for
cbc_choicesobjects if not specified.- panelID
Name of the panel ID column for panel data. Auto-detected as "respID" for multi-respondent
cbc_choicesobjects.- alpha
Significance level for power calculations. Defaults to 0.05.
- return_models
If TRUE, includes full model objects in returned list. Defaults to FALSE.
- n_cores
Number of cores for parallel processing. Defaults to
parallel::detectCores() - 1.- ...
Additional arguments passed to
logitr::logitr().
Value
A cbc_power object containing:
power_summary: Data frame with sample sizes, coefficients, estimates, standard errors, t-statistics, and powermodels: List of estimated models (ifreturn_models = TRUE)sample_sizes: Vector of sample sizes testedn_breaks: Number of breaks usedalpha: Significance level used
Examples
library(cbcTools)
# Create profiles and design
profiles <- cbc_profiles(
price = c(1, 2, 3),
type = c("A", "B", "C"),
quality = c("Low", "High")
)
design <- cbc_design(profiles, n_alts = 2, n_q = 6)
# Simulate choices
priors <- cbc_priors(profiles, price = -0.1, type = c(0.5, 0.2), quality = 0.3)
choices <- cbc_choices(design, priors)
# Run power analysis
power_results <- cbc_power(choices, n_breaks = 8)
#> Auto-detected parameters: price, type, quality
#> Using 'respID' as panelID for panel data estimation.
#> Estimating models using 3 cores...
#> Model estimation complete!
# View results
print(power_results)
#> CBC Power Analysis Results
#> ==========================
#>
#> Sample sizes tested: 12 to 100 (8 breaks)
#> Significance level: 0.050
#> Parameters: price, typeB, typeC, qualityHigh
#>
#> Power summary (probability of detecting true effect):
#>
#> n = 12:
#> price : Power = 0.091, SE = 0.2111
#> typeB : Power = 0.441, SE = 0.3734
#> typeC : Power = 0.089, SE = 0.4166
#> qualityHigh : Power = 0.161, SE = 0.3455
#>
#> n = 38:
#> price : Power = 0.347, SE = 0.1164
#> typeB : Power = 0.894, SE = 0.2461
#> typeC : Power = 0.079, SE = 0.2339
#> qualityHigh : Power = 0.227, SE = 0.1923
#>
#> n = 50:
#> price : Power = 0.525, SE = 0.1026
#> typeB : Power = 0.911, SE = 0.2105
#> typeC : Power = 0.066, SE = 0.2026
#> qualityHigh : Power = 0.321, SE = 0.1656
#>
#> n = 75:
#> price : Power = 0.420, SE = 0.0812
#> typeB : Power = 0.984, SE = 0.1670
#> typeC : Power = 0.120, SE = 0.1637
#> qualityHigh : Power = 0.354, SE = 0.1390
#>
#> n = 100:
#> price : Power = 0.566, SE = 0.0706
#> typeB : Power = 0.990, SE = 0.1453
#> typeC : Power = 0.169, SE = 0.1420
#> qualityHigh : Power = 0.597, SE = 0.1161
#>
#> Use plot() to visualize power curves.
#> Use summary() for detailed power analysis.
plot(power_results)