cbcTools provides a complete toolkit for designing and analyzing choice-based conjoint (CBC) experiments. This article walks through the entire workflow from defining attributes to creating and inspecting designs and determining sample size requirements, providing a quick start guide for new users and an overview of the package’s capabilities. Other articles cover more details on each step.
The cbcTools Workflow
The package supports a step-by-step process for developing choice experiment designs:

Each step uses functions that begin with cbc_ and builds
on the previous step:
-
Generate Profiles →
cbc_profiles()- Define attributes and levels -
Specify Priors →
cbc_priors()- Specify prior preference assumptions (optional) -
Generate Designs →
cbc_design()- Create choice question design -
Inspect Designs →
cbc_inspect()- Evaluate design quality -
Simulate Choices →
cbc_choices()- Generate realistic choice data -
Assess Power →
cbc_power()- Determine sample size requirements
Let’s walk through each step with a complete example. Imagine we’re designing a choice experiment to understand consumer preferences for apples. We want to study how price, type, and freshness influence purchase decisions.
Step 1: Generate Profiles
Start by defining the attributes and levels for your experiment:
profiles <- cbc_profiles(
price = c(1.0, 1.5, 2.0, 2.5, 3.0), # Price per pound ($)
type = c('Fuji', 'Gala', 'Honeycrisp'),
freshness = c('Poor', 'Average', 'Excellent')
)
profiles
#> CBC Profiles
#> ============
#> price : Continuous (5 levels, range: 1.00-3.00)
#> type : Categorical (3 levels: Fuji, Gala, Honeycrisp)
#> freshness : Categorical (3 levels: Poor, Average, Excellent)
#>
#> Profiles: 45
#> First few rows:
#> profileID price type freshness
#> 1 1 1.0 Fuji Poor
#> 2 2 1.5 Fuji Poor
#> 3 3 2.0 Fuji Poor
#> 4 4 2.5 Fuji Poor
#> 5 5 3.0 Fuji Poor
#> 6 6 1.0 Gala Poor
#> ... and 39 more rowsThis creates all possible combinations of attribute levels - our “universe” of possible products to include in choice questions.
See the Generating Profiles article for more details and options on defining profiles, such as including restrictions.
Step 2: Specify Priors
Specify your assumptions about consumer preferences based on theory, literature, or pilot studies. These can be used for generating designs that incorporate these expected preferences as well as simulating choices for a given design.
priors <- cbc_priors(
profiles = profiles,
price = -0.25, # Negative = people prefer lower prices
type = c(0.5, 1), # Gala and Honeycrisp preferred over Fuji (reference)
freshness = c(0.6, 1.2) # Average and Excellent preferred over Poor (reference)
)
priors
#> CBC Prior Specifications:
#>
#> price:
#> Continuous variable
#> Levels: 1, 1.5, 2, 2.5, 3
#> Fixed parameter
#> Coefficient: -0.25
#>
#> type:
#> Categorical variable
#> Levels: Fuji, Gala, Honeycrisp
#> Reference level: Fuji
#> Fixed parameter
#> Gala: 0.5
#> Honeycrisp: 1
#>
#> freshness:
#> Categorical variable
#> Levels: Poor, Average, Excellent
#> Reference level: Poor
#> Fixed parameter
#> Average: 0.6
#> Excellent: 1.2Understanding Reference Levels
For categorical attributes, the reference level is set by the
first level defined in cbc_profiles(), which in
this case is "Fuji" for Type and
"Poor" for Freshness. This would imply the
following for the above set of priors:
- Type: Fuji (reference), Gala (+0.5), Honeycrisp (+1.0)
- Freshness: Poor (reference), Average (+0.6), Excellent (+1.2)
See the Specifying Priors article for more details and options on defining priors.
Step 3: Generate Designs
Create the set of choice questions that respondents will see. Designs
are created with standard encoding (categorical variables). You can
convert to dummy or effects coding using cbc_encode():
design <- cbc_design(
profiles = profiles,
method = "stochastic", # D-optimal method
n_alts = 3, # 2 alternatives per choice question
n_q = 6, # 6 questions per respondent
n_resp = 300, # 300 respondents
priors = priors # Use our priors for optimization
)
design
#> Design method: stochastic
#> Encoding: standard
#> Structure: 300 respondents × 6 questions × 3 alternatives
#> Profile usage: 14/45 (31.1%)
#> D-error: 0.814898
#>
#> 💡 Use cbc_inspect() for a more detailed summary
#>
#> First few rows of design:
#> profileID blockID respID qID altID obsID price type freshness
#> 1 40 1 1 1 1 1 3.0 Gala Excellent
#> 2 16 1 1 1 2 1 1.0 Fuji Average
#> 3 4 1 1 1 3 1 2.5 Fuji Poor
#> 4 45 1 1 2 1 2 3.0 Honeycrisp Excellent
#> 5 20 1 1 2 2 2 3.0 Fuji Average
#> 6 6 1 1 2 3 2 1.0 Gala Poor
#> ... and 5394 more rowsThe design generated is sufficient for a full survey for
n_resp respondents. cbcTools offers
several design methods, each with their own trade-offs:
-
"random": Random profiles for each respondent. -
"shortcut": Frequency-balanced, often results in minimal overlap within choice questions. -
"minoverlap": Prioritizes minimizing attribute overlap within choice questions. -
"balanced": Optimizes both frequency balance and pairwise attribute interactions. -
"stochastic": Minimizes D-error by randomly swapping profiles. -
"modfed": Minimizes D-error by swapping out all possible profiles (slower, more thorough). -
"cea": Minimizes D-error by attribute-by-attribute swapping.
All design methods ensure:
- No duplicate profiles within any choice set.
- No duplicate choice sets within any respondent.
- Dominance removal (if enabled) eliminates choice sets with dominant alternatives.
See the Generating Designs article for more details and options on generating experiment designs, such as including “no choice” options, using labeled designs, removing dominant options, and details about each design algorithm.
Step 4: Inspect Design
Use the cbc_inspect() function to evaluate the quality
and properties of your design. Key things to look for:
- D-error: Lower values indicate more efficient designs
- Balance: Higher scores indicate better attribute level balance
- Overlap: Lower scores indicate less attribute overlap within questions
- Profile usage: Higher percentages indicate better use of available profiles
See cbc_inspect
for more details.
cbc_inspect(design)
#> DESIGN SUMMARY
#> =========================
#>
#> STRUCTURE
#> ================
#> Method: stochastic
#> Created: 2026-06-24 10:41:52
#> Respondents: 300
#> Questions per respondent: 6
#> Alternatives per question: 3
#> Total choice sets: 1800
#> Profile usage: 14/45 (31.1%)
#>
#> SUMMARY METRICS
#> =================
#> D-error (with priors): 0.814898
#> D-error (null model): 0.733760
#> (Lower values indicate more efficient designs)
#>
#> Overall balance score: 0.747 (higher is better)
#> Overall overlap score: 0.000 (lower is better)
#>
#> VARIABLE ENCODING
#> =================
#> Format: Standard (categorical) (type, freshness)
#> 💡 Use cbc_encode() to convert to dummy or effects coding
#>
#> ATTRIBUTE BALANCE
#> =================
#> Overall balance score: 0.747 (higher is better)
#>
#> Individual attribute level counts:
#>
#> price:
#>
#> 1 2 2.5 3
#> 1500 300 600 3000
#> Balance score: 0.527 (higher is better)
#>
#> type:
#>
#> Fuji Gala Honeycrisp
#> 2100 1800 1500
#> Balance score: 0.857 (higher is better)
#>
#> freshness:
#>
#> Poor Average Excellent
#> 2100 1800 1500
#> Balance score: 0.857 (higher is better)
#>
#> ATTRIBUTE OVERLAP
#> =================
#> Overall overlap score: 0.000 (lower is better)
#>
#> Counts of attribute overlap:
#> (# of questions with N unique levels)
#>
#> price: Continuous variable
#> Questions by # unique levels:
#> 1 (complete overlap): 0.0% (0 / 1800 questions)
#> 2 (partial overlap): 66.7% (1200 / 1800 questions)
#> 3 (partial overlap): 33.3% (600 / 1800 questions)
#> 4 (no overlap): 0.0% (0 / 1800 questions)
#> Average unique levels per question: 2.33
#>
#> type: Categorical variable
#> Questions by # unique levels:
#> 1 (complete overlap): 0.0% (0 / 1800 questions)
#> 2 (partial overlap): 16.7% (300 / 1800 questions)
#> 3 (no overlap): 83.3% (1500 / 1800 questions)
#> Average unique levels per question: 2.83
#>
#> freshness: Categorical variable
#> Questions by # unique levels:
#> 1 (complete overlap): 0.0% (0 / 1800 questions)
#> 2 (partial overlap): 16.7% (300 / 1800 questions)
#> 3 (no overlap): 83.3% (1500 / 1800 questions)
#> Average unique levels per question: 2.83Step 5: Simulate Choices
Generate realistic choice data to test your design with the
cbc_choices() function. By default, random choices are
made, but if you provide priors with the priors argument,
choices will be made according to the utility model defined by your
priors:
# Simulate choices using our priors
choices <- cbc_choices(design, priors = priors)
choices
#> CBC Choice Data
#> ===============
#> Encoding: standard
#> Observations: 1800 choice tasks
#> Alternatives per task: 3
#> Respondents: 300
#> Questions per respondent: 6
#> Total choices made: 1800
#>
#> Simulation method: utility_based
#> Original design D-error: 0.814898
#> Priors: Used for utility-based simulation
#> Simulated at: 2026-06-24 10:41:53
#>
#> Choice rates by alternative:
#> Alt 1: 32.6% (587 choices)
#> Alt 2: 33.6% (604 choices)
#> Alt 3: 33.8% (609 choices)
#>
#> First few rows:
#> profileID blockID respID qID altID obsID price type freshness choice
#> 1 40 1 1 1 1 1 3.0 Gala Excellent 1
#> 2 16 1 1 1 2 1 1.0 Fuji Average 0
#> 3 4 1 1 1 3 1 2.5 Fuji Poor 0
#> 4 45 1 1 2 1 2 3.0 Honeycrisp Excellent 1
#> 5 20 1 1 2 2 2 3.0 Fuji Average 0
#> 6 6 1 1 2 3 2 1.0 Gala Poor 0
#> ... and 5394 more rowsTaking a look at some quick summaries, you can see that the simulated choice patterns align with our priors - lower prices, preferred apple types, and better freshness should be chosen more often (not always for all levels though as there is some level of randomness involved):
choices_cat <- choices
# Filter for the chosen rows only
choices_cat <- choices_cat[which(choices_cat$choice == 1), ]
# Counts of choices made for each attribute level
table(choices_cat$price)
#>
#> 1 2 2.5 3
#> 608 125 167 900
table(choices_cat$type)
#>
#> Fuji Gala Honeycrisp
#> 589 541 670
table(choices_cat$freshness)
#>
#> Poor Average Excellent
#> 514 569 717See the Simulating Choices article for more details and options on inspeciting and comparing different experiment designs.
Step 6: Assess Power
Determine if your sample size provides adequate statistical power.
The cbc_power() function auto-determines the attributes in
your design and estimates multiple logit models using incrementally
increasing sample sizes to assess power:
power <- cbc_power(choices)
power
#> CBC Power Analysis Results
#> ==========================
#>
#> Sample sizes tested: 30 to 300 (10 breaks)
#> Significance level: 0.050
#> Parameters: price, typeGala, typeHoneycrisp, freshnessAverage, freshnessExcellent
#>
#> Power summary (probability of detecting true effect):
#>
#> n = 30:
#> price : Power = 0.989, SE = 0.0929
#> typeGala : Power = 0.473, SE = 0.2126
#> typeHoneycrisp: Power = 0.992, SE = 0.2262
#> freshnessAverage: Power = 0.776, SE = 0.2335
#> freshnessExcellent: Power = 1.000, SE = 0.2419
#>
#> n = 90:
#> price : Power = 1.000, SE = 0.0536
#> typeGala : Power = 0.993, SE = 0.1213
#> typeHoneycrisp: Power = 1.000, SE = 0.1300
#> freshnessAverage: Power = 0.996, SE = 0.1292
#> freshnessExcellent: Power = 1.000, SE = 0.1354
#>
#> n = 180:
#> price : Power = 1.000, SE = 0.0378
#> typeGala : Power = 0.998, SE = 0.0853
#> typeHoneycrisp: Power = 1.000, SE = 0.0900
#> freshnessAverage: Power = 1.000, SE = 0.0919
#> freshnessExcellent: Power = 1.000, SE = 0.0965
#>
#> n = 240:
#> price : Power = 1.000, SE = 0.0326
#> typeGala : Power = 1.000, SE = 0.0736
#> typeHoneycrisp: Power = 1.000, SE = 0.0781
#> freshnessAverage: Power = 1.000, SE = 0.0787
#> freshnessExcellent: Power = 1.000, SE = 0.0830
#>
#> n = 300:
#> price : Power = 1.000, SE = 0.0292
#> typeGala : Power = 1.000, SE = 0.0660
#> typeHoneycrisp: Power = 1.000, SE = 0.0703
#> freshnessAverage: Power = 1.000, SE = 0.0707
#> freshnessExcellent: Power = 1.000, SE = 0.0747
#>
#> Use plot() to visualize power curves.
#> Use summary() for detailed power analysis.You can easily visualize the results as well using the
plot() function:
plot(power, type = "power", power_threshold = 0.9)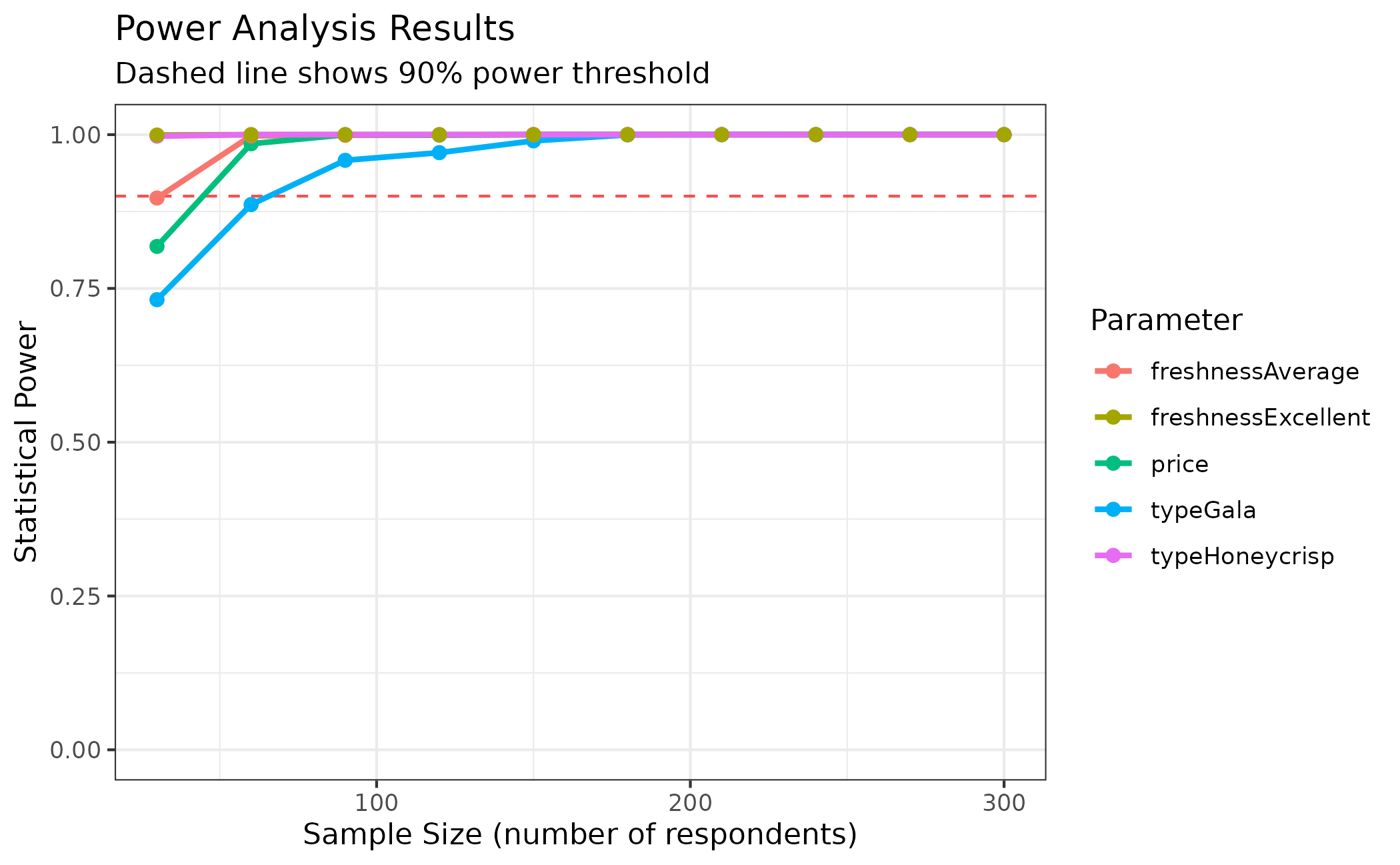
Finally, using the summary() function you can determine
the exact size required to identify each attribute:
summary(power, power_threshold = 0.9)
#> CBC Power Analysis Summary
#> ===========================
#>
#> Sample size requirements for 90% power:
#>
#> price : n >= 30 (achieves 98.9% power, SE = 0.0929)
#> typeGala : n >= 60 (achieves 95.4% power, SE = 0.1479)
#> typeHoneycrisp : n >= 30 (achieves 99.2% power, SE = 0.2262)
#> freshnessAverage: n >= 60 (achieves 98.7% power, SE = 0.1608)
#> freshnessExcellent: n >= 30 (achieves 100.0% power, SE = 0.2419)See the Power article for more details and options on conducting power analyses to better understand your experiment designs.